
 BN News - bacninhmoi.com
BN News - bacninhmoi.com
Làm thế nào để xây dựng một Recommender System (RS) - Phần 3
Hãy tưởng tượng rằng chúng ta cùng là thành viên thuộc một nhóm thích ngắm hot girl trên Facebook thì rõ ràng chúng ta đều có chung một sở thích là thích ngắm các cô gái chân dài phải không nào. Tuy nhiên sức người có hạn mà mĩ nhân lại quá nhiều nên chúng ta cần phải dựa vào sức mạnh cộng đồng để ngắm được nhiều mỹ nhân hơn. Một ví dụ vui như vậy để các bạn hiểu bản chất của lọc cộng tác dựa trên người dùng chính là tìm người dùng có sở thích tương tự với mình và gợi ý những thứ họ thích cho mình. OK chưa các bạn, bây giờ chúng ta sẽ cùng nhau xem từng bước xây dựng một hẹ gợi ý sử dụng User Based collaborative Filtering như thế nào nhé:
- Thu thập dữ liệu mẫu và xây dựng ma trận users - items
- Đối với mỗi user, ta quan tâm đến các items đã được users đó rating
- Đối với mỗi item được user đó rating tìm được K users khác cũng rating item đó
- Tính toán độ tương tự giữa các users và đánh score cho các items chưa được user hiện tại rating
- Gợi ý cho người dùng hiện tại những items có rating cao nhất
OK giờ chúng ta bắt đầu nhé
Thu thập dữ liệu mẫu
Để tiện cho việc các bạn theo dõi bài viết, ở đây mình vẫn sử dụng tập dữ liệu bài hát của Last.fm giống như bài trước. Tập dữ liệu này bao gồm các thông tin về người dùng và sở thích âm nhạc của họ. Cụ thể trong phần này chúng ta sẽ cần sử dụng một file dữ liệu lưu ma trận trọng số users - items thể hiện user nào đã từng nghe bài hát của tác giả nào. Các bước xây dựng ma trận users - items đã được mô tả rất kĩ ở phần trước. Mình không trình bay lại ở đây nữa mà sẽ đi sâu vào việc triển khai thuật toán User Based Collaborative Filtering luôn nhé. Kết quả của quá trình xây dựng ma trận users - items là một ma trận như sau: 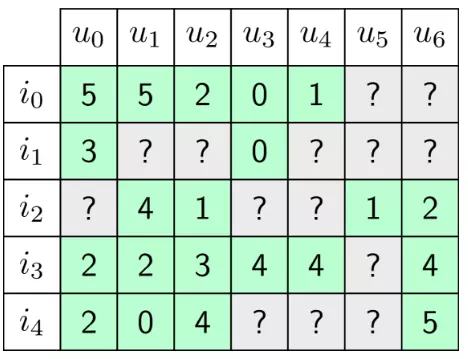
Bản chất của phương pháp
Về bản chất của phương pháp Lọc cộng tác dựa trên users đó là việc xác định độ tương đồng của các người dùng với nhau, (ví dụ như cùng thích ngắm gái hoặc ngắm trai chẳng hạn). Tuy nhiên có thể thấy được rằng dữ liệu duy nhất mà chúng ta có đó chính là Utility Matrix như ở trên, tức là xem xét xem từng cột của ma trận giống với các cột còn lại như thế nào để từ đó đưa ra gợi ý cho người dùng. Từ trực quan chúng ta cũng có thể thấy được răng mỗi user có xu hướng thích một nhóm các item riêng biệt. Ví dụ như với ma trận ở trên, U1 và U2 có vẻ như thích các items là I1, I2 và I3 hơn với các item khác. Hãy tưởng tượng như bạn đang nghe nhạc thì có những người dùng thích nhạc trẻ, có người lại thích nhạc không lời vậy. Tuy nhiên như đã nói ở trên, dữ liệu duy nhất mà chúng ta sử dụng để tính toán độ tương tự chính là cái ma trận Utility Matrix nhưng rõ ràng làm sao chúng ta có thể tính toán được nếu như ma trận của chúng ta đang bị thiếu quá nhiều, thể hiện ở các ô có hình ***dấu hỏi chấm ?***. Chính vì lý do đó nên trước khi đi tính toán độ tương tự của các user, chúng ta cần phải điền đầy đủ các dấu hỏi đó mà nó không làm ảnh hưởng đến độ tương tự - bước này gọi là bước chuẩn hóa dữ liệu.
Bạn đừng lầm tưởng là ***Nếu đã điền đầy đủ Matrix rồi thì cần gì dự đoán nữa???***, đây chỉ là bươc chuẩn hóa để phục vụ cho việc tính toán độ tương tự mà thôi. Việc dự đoán lại các ô đó chúng ta sẽ làm sau khi tính toán được độ tương tự. Ái chà, nghe có vẻ rắc rối rồi đó, vì làm sao mà chúng ta có thể điển các giá trị để phản ánh độ tương tự một cách chính xác nhất. Bạn có thể nghĩ đến một vài giải pháp như sau:
- Điền giá trị 0: đây là cách siêu đơn giản nhưng lại quá nguy hiểm vì giá trị 0 đồng nghĩa với việc user rất không thích item đó. Nên thử tìm cách khác xem sao
- Lấy giá trị trung bình của khoảng rating: Thay vì chẳng biết thằng user này rất thích (5 star) hay là rất ghét (0 star) thì ta có thể nghĩ đến việc lấy giá trị trung gian của khoảng này để điền vào các ô có giá trị còn thiếu. Cách này nghe có vẻ là khá công bằng tuy nhiên việc lấy giá trị trung gian thế này cũng chưa thật sự ổn lắm. Sẽ hơi thiệt cho những người thích item đó vì bị đánh giá thấp sản phẩm mình yeu thích, và cũng hơi bất công cho những người không thích item đó khi phải đánh giá cao cho sản phẩm mình không thích phải không nào. Vậy phải tìm giải pháp khác thôi
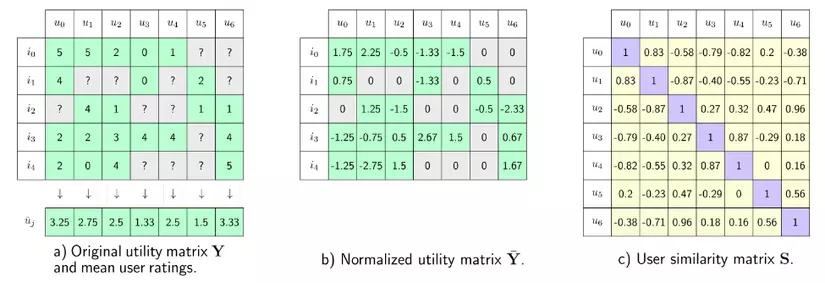
- Lấy trung bình của các rating của user: Điều này giống như việc xem xét xem cộng đồng mạng sẽ rating như thế nào lên các sản phẩm trước đó. Tự đó sẽ lấy giá trị trung bình của việc rating để chuẩn hóa dữ liệu. Cụ thể chúng ta sẽ trừ lần lượt các rating của user đó lên các item cho giá trị trung bình. Điều này dẫn đến sẽ có những giá trị rating âm (tức nhỏ hơn giá trị trung bình) thể hiện user đó không thích item. Điều ngược lại thể hiển với các rating dương. Việc cuối cùng là điền các giá trị 0 vào cho các ô chưa biết kết quả và tiến hành đánh giá độ tương tự. Các bạn có thể tham khảo các bước làm trong hình sau:
Xác định độ tương tự và dự đoán
Như mình đã trình bày trong phần trên thì bản chất của giải thuật lọc cộng tác dựa trên người dùng là sẽ tìm ra các người dùng có lịch sử thao tác (ví dụ như nghe nhạc, mua hàng online, hay ngắm gái xinh trên Facebook) tương đồng nhất với người dùng hiện tại rồi gợi ý các sản phẩm phù hợp nhất cho họ. Để làm được việc đó chúng ta cần định nghĩa 2 vec tơ trọng số để biểu diễn độ tương đồng. Một vector thể hiện lịch sử của người dùng hiện tại và vector còn lại sẽ thể hiện những người dùng có độ tương đồng nhất về lịch sử hoạt động để từ đó chúng ta định nghĩa một hàm đo sự tương đồng của lịch sử người dùng hiện tại với các người dùng còn lại như sau:
# Function to get similarity scores
def similarity_score(history, similarities):
return sum(history*similarities) / sum(similarities)
Trở lại đoạn code giống như bài hôm trước chúng ta sẽ load dữ liệu từ tập Last.fm và chúng ta có thể dễ dàng nhận ra rằng bản thân file dữ liệu gốc đã làm nên một ma trận độ tương tự giữa các users và việc chúng ta cần làm đơn giản chỉ là loại bỏ đi cột header. Chúng ta thực hiện nó như sau:
data = pd.read_csv('data.csv')
data_sims = pd.DataFrame(index=data.index,columns=data.columns)
data_sims.ix[:,:1] = data.ix[:,:1]
Bây giờ chúng ta sẽ sử dụng hàm tính điểm độ tương tự nêu trên để điền đầy đủ các ô còn thiếu trong ma trận độ tương tự của chúng ta. Ở đây mình chỉ sử dụng một cách đơn giản nhất để đánh dấu các items có trong lịch sử của người dùng là cho chúng bằng 0.
for i in range(0, len(data_sims.index)):
for j in range(1, len(data_sims.columns)):
user = data_sims.index[i]
product = data_sims.columns[j]
if data.ix[i][j] == 1:
data_sims.ix[i][j] = 0
else:
product_top_names = data_neighbours.ix[product][1:10]
product_top_sims = data_item_base_frame.ix[product].order(ascending=False)[1:10]
user_purchases = data_item_base.ix[user, product_top_names]
data_sims.ix[i][j] = similarity_score(user_purchases, product_top_sims)
Kết thúc bước này chúng ta đã có ma trận độ tương tự và việc cần làm là phải lấy những items ra để gợi ý cho người dùng hiện tại. Đây chính là bươc cuối cùng để chúng ta nhìn thấy được kết quả vô cùng thú vị
# Get the top songs
data_recommend = pd.DataFrame(index=data_sims.index, columns=['user','1','2','3','4','5','6'])
data_recommend.ix[0:,0] = data_sims.ix[:,0]
Kết quả
Sau khi thực hiện điền được các ô còn trống trong ma trận Users - Items chúng ta sẽ tìm được các items có độ tương tự gần nhất đối với từng users. Sau đây là kết quả cho tập users ở đoạn code bên trên.
user 1 2 3
0 1 flogging molly coldplay aerosmith
1 33 red hot chili peppers kings of leon peter fox
2 42 oomph! lacuna coil rammstein
3 51 the subways the kooks franz ferdinand
4 62 jack johnson incubus mando diao
5 75 hoobastank papa roach sum 41
6 130 alanis morissette the smashing pumpkins pearl jam
7 141 machine head sonic syndicate caliban
8 144 editors nada surf the strokes
9 150 placebo the subways eric clapton
10 205 in extremo nelly furtado finntroll
Kết luận
Như vậy chúng ta đã cùng nhau tìm hiểu phần còn lại của phương pháp lọc cộng tác và mình hi vọng rằng nó có thể giúp bạn hiểu hơn về cách mà một hệ thống gợi ý hoạt động và có thể áp dụng được giải thuật tuyệt vời này trong các dự án thực tế. Ngoài giải thuật lọc cộng tác nổi tiếng này chúng ta còn một phương pháp rất nổi tiếng nữa mà mình rất hi vọng được trình bày với các bạn trong những bài tiếp theo đó chính là phương pháp phân rã ma trận. Rất mong được các bạn theo dõi và đón đọc
Ý kiến bạn đọc
- Đang truy cập29
- Hôm nay12,442
- Tháng hiện tại279,215
- Tổng lượt truy cập13,752,327