
 BN News - bacninhmoi.com
BN News - bacninhmoi.com
Làm thế nào để xây dựng một Recommender System (RS) - Phần 2
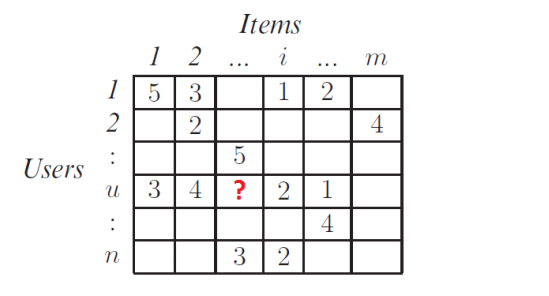
Từ phần này chúng ta bắt đầu đi sâu hơn xây dựng một hệ gợi ý đơn giản sử dụng phương pháp lọc công tác với từng hướng tiếp cận của nó đó là:
- Lọc cộng tác dựa trên người dùng - User based approach
- Lọc cộng tác dựa trên sản phẩm - Item based approach
Và không thể thiếu đó là phần cài đặt dựa trên ngôn ngữ Python nữa. Các bạn đã sẵn sàng chưa nào. Chúng ta cùng nhau bắt đầu nhé
Giải thuật lọc cộng tác là gì???
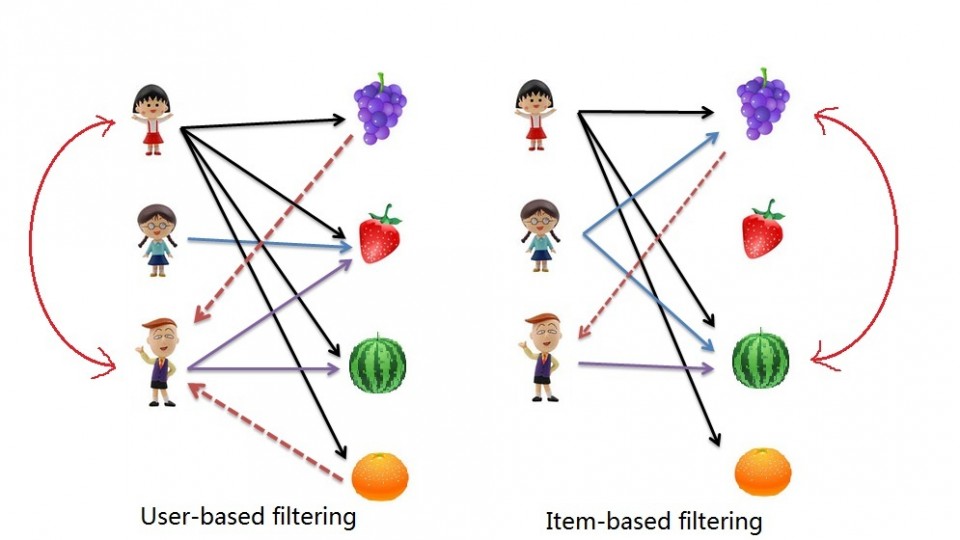 Như đã nói qua ở bài viết trước thì chúng ta có thể hình dung rằng lọc cộng tác được xây dựng dựa trên lý thuyết về sự đồng sở thích của những người dùng khác nhau. Lý thuyết này có thể hiểu đơn giản như sau:
Như đã nói qua ở bài viết trước thì chúng ta có thể hình dung rằng lọc cộng tác được xây dựng dựa trên lý thuyết về sự đồng sở thích của những người dùng khác nhau. Lý thuyết này có thể hiểu đơn giản như sau:
Nếu hai người dùng u1 và u2 đánh giá cho n sản phẩm tương tự nhau hoặc có hành vi tương tự nhau như xem, mua, nghe... thì họ sẽ có đánh giá hoặc các hành vi tương tự với các sản phẩm khác Nói màu mè một chút là Hãy cho tôi biết bạn bè của bạn là ai, tôi sẽ nói cho bạn biết bạn là người như thế nào.
Luật số lớn và lý thuyết đám đông
Đọc định nghĩa trên bạn có thấy gì đó gian dối và hơi chủ quan không. Làm sao mà chỉ có vài điểm chung trong sở thích mà lại có thể kết luận các sở thích khác của họ cũng giống nhau được. Tất nhiên không phải lúc nào điều đó cũng đúng 100% đâu, ngay cả những ông lớn như Facebook hay Google đôi khi còn đưa ra những gợi ý ngớ ngẩn nữa mà đúng không nào. Điều này được xây dựng dựa trên luật số lớn và lý thuyết đám đông. Đừng vội đọc lướt qua điểm này nhé vì nó quan trọng lắm đấy. Đám đông thì không phải lúc nào cũng đúng đâu, chỉ có những đám đông liên quan đến mình mới có thể sử dụng để gợi ý thôi - thế mới có chữ lọc ở cái tên kia kìa.
Collaborative Filtering vs Content based approach
Rõ ràng có một số đối tượng rất dễ xác định những đối tượng khác tương đồng nội dung với nó. Chẳng hạn như Facebook gợi ý những người bạn cùng quê quán với bạn, cùng học Bách Khoa với bạn, cùng hội ngắm gái xinh với bạn chẳng hạn. Những thông tin đó rất dễ dàng so sánh, nhưng với những đối tượng khó có thể xác định được nội dung của nó bằng máy tính như một bài nhạc (nhạc không lời thì càng bó tay hơn), một bài báo.... thì rõ ràng chúng ta cần đến giải thuật lọc cộng tác thần thánh này. OK bạn đã hiểu lý do tại sao chúng ta lại sử dụng lọc cộng tác rồi chứ. Bây giờ chúng ta sẽ tiếp túc với một vài khái niệm cơ bản trước khi đi vào thực hành nhé.
Tính toán độ tương tự
Rõ rằng chúng ta không thể xem xét độ tương tự giữa các đối tượng bằng cảm tính được. Như bài viết trước mình đã chia sẻ, chúng ta cần phải mô hình hóa bằng ma trận users - items và mỗi dòng của nó là một vecto. Tất nhiên chúng ta cần một cơ sở toán học cụ thể để xác định độ tương tự này dựa trên ma trận users - items đó và đại lượng này được gọi là khoảng cách
- Khoảng cách càng nhỏ => càng gần nhau => độ tương tự càng lớn
- Khoảng cách càng lớn => em đi xa quá => chúng ta không thuộc về nhau => độ tương tự càng nhỏ
Bằng cách hiểu như vậy chúng ta có thể hiểu độ đo tương tự giống như nghịch đảo của khoảng cách sử dụng để tính toán đại lượng này. Chúng ta có một số loại khoảng cách tiêu biểu như sau
Khoảng cách Ơ-clit và Minkowski:
Chúng ta hẳn ai cũng quá quen thuộc với công thức tính khoảng cách giữa hai điểm trên một mặt phẳng tọa độ - đây chính là khoảng cách Ơ-clit: 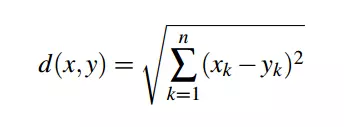 Tất nhiên đời không như mơ, và dữ liệu thực tế thường là các vecto thể hiện mối quan hệ giữa một user và rất nhiều items. Chính vì thế Minkowski đã tổng quát hóa thành một khoảng cách cho vecto r chiều
Tất nhiên đời không như mơ, và dữ liệu thực tế thường là các vecto thể hiện mối quan hệ giữa một user và rất nhiều items. Chính vì thế Minkowski đã tổng quát hóa thành một khoảng cách cho vecto r chiều 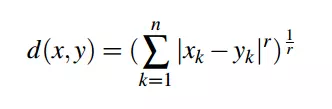
Khoảng cách Cosin
Khoảng cách giữa hai vecto được đo bằng cosin của góc tạo thành giữa chúng. Công thức cũng không có gì quá khó hiểu 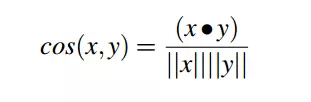 Còn nhiều khoảng cách nữa chúng ta có thể áp dụng để tính độ đo tương tự. Mọi người chịu khó tìm hiểu trên Google nhé. Mình không tiện kể hết ở đây đến tránh sự tổn thương con mắt của mọi người khi phải đọc những công thức toán học này. OK giờ chúng ta bắt đầu vào phần quan trọng nhất của bài viết này. Đó chính là thực hành xây dựng một hệ gợi ý bài hát. Các bạn đã sẵn sàng chiến đấu chưa nào
Còn nhiều khoảng cách nữa chúng ta có thể áp dụng để tính độ đo tương tự. Mọi người chịu khó tìm hiểu trên Google nhé. Mình không tiện kể hết ở đây đến tránh sự tổn thương con mắt của mọi người khi phải đọc những công thức toán học này. OK giờ chúng ta bắt đầu vào phần quan trọng nhất của bài viết này. Đó chính là thực hành xây dựng một hệ gợi ý bài hát. Các bạn đã sẵn sàng chiến đấu chưa nào
Xây dựng Recommender System đơn giản với Python
Tập dữ liệu bài hát trên Last.fm
Chúng ta sẽ sử dụng một tập dữ liệu khá tuyệt vời về lĩnh vực âm nhạc đó chinh là tập dữ liệu âm nhạc Last.fm. Tập dữ liệu này bao gồm các thông tin về người dùng và sở thích âm nhạc của họ. Cụ thể trong phần này chúng ta sẽ cần sử dụng một file dữ liệu lưu ma trận trọng số users - items thể hiện user nào đã từng nghe bài hát của tác giả nào.[Các bạn có thể download tập dữ liệu này ở đây. Sau khi download tập dữ liệu này về, chúng ta sẽ tiến hành khai phá dữ liệu từ nó. OK chúng ta tiếp tục thôi
Đọc dữ liệu
Tập dữ liệu của chúng ta gồm có 1257 người dùng và 286 tác giả ở đây các tác giả có thể coi là các items. Đầu tiên chúng ta đọc dữ liệu từ file data.csv bằng thư viện pandas
import pandas as pd
if __name__ == '__main__':
data = pd.read_csv('data.csv')
print data.shape
print data.head(8).ix[:,0:6 ]
Do file dữ liệu khá dài nên chúng ta chỉ đọc thử một vài dữ liệu mà thôi. Ở đây in dữ liệu của 8 dòng và 6 cột đầu tiên trong tập dữ liệu. Kết quả như sau: 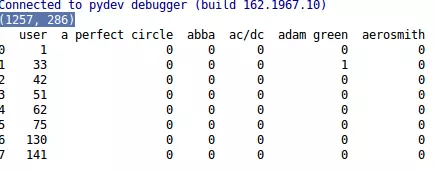 Những ô bằng 0 thể hiện usser chưa từng nghe nhạc của tác giả đó. Những ô có giá trị bằng 1 thể hiện user***đã từng nghe*** nhạc của tác giả này. Cũng khá dễ hiểu phải không các bạn. Chính từ tập dữ liệu này chúng ta sẽ xây dựng giải thuật lọc cộng tác của chúng ta.
Những ô bằng 0 thể hiện usser chưa từng nghe nhạc của tác giả đó. Những ô có giá trị bằng 1 thể hiện user***đã từng nghe*** nhạc của tác giả này. Cũng khá dễ hiểu phải không các bạn. Chính từ tập dữ liệu này chúng ta sẽ xây dựng giải thuật lọc cộng tác của chúng ta.
Lọc cộng tác dựa trên các item tương tự - Item Based Collaborative Filtering
Chúng ta không cần quan tâm đến user trong giải thuật lọc cộng tác dựa trên các item. Mục đích của phương pháp này chính là dựa vào dữ liệu trong quá khứ của các items (ở đây là chính là các nghệ sĩ) để tìm ra các nghệ sĩ có độ tương đồng và gợi ý cho người dùng. Chính vì thế nó không cần quan tâm đến người dùng hiện tại. Chính vì thế chúng ta có thể drop cột "user" đi.
# --- Start Item Based Recommendations --- #
# Drop any column named "user"
data_item_base = data.drop('user', 1)
Tính toán độ đo tương tự
Trước khi tiến hành tính toán độ đo tương tự, chúng ta cần phải khởi tạo một cấu trúc dữ liệu để có thể lưu trữ chúng. Chính là một ma trận vuông thể hiện sự tương đồng của các cặp items - items. Điều đó làm mình nghĩ ngay đến DataFrame của Python. Và chúng ta sẽ tiến hành việc nó như sau:
data_item_base_frame = pd.DataFrame(index=data_item_base.columns, columns=data_item_base.columns)
print data_item_base_frame.head(6).ix[:,0:6]
Như vậy chúng ta đã khởi tạo được một DataFrame để lưu trử độ tương tự giữa các items với nhau. Xem hình thù của nó một chút nhé 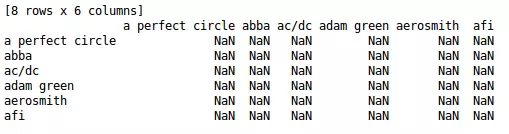
OK bây giờ chúng ta sẽ cùng nhau xem xét đến việc tính toán độ tương tự giữa các cặp items - items. Chúng ta đã được đề cập đến từ phần đầu tiên của bài viết rằng độ đo tương tự có thể hiểu là nghịch đảo của khoảng cách. Chúng ta có thể áp dụng các loại khoảng cách khác nhau cho tính toán độ đo tương tự. Ở đây để demo mình sử dụng khoảng cách Cosin cũng đã được đề cập ở phần trên. Chúng ta thực sự không cần care nhiều về việc tính toán khoảng các cosin như thế nào bởi vì việc này đã được hỗ trợ rất đầy đủ bởi thư viện SciPy của Python rồi. Trước tiên chúng ta cần phải import thư viện này đã nhé
from scipy.spatial.distance import cosine
Sau đó chúng ta bắt đầu tính toán độ tương tự cho từng items. Chúng ta sử dụng hai vòng lặp để tính toán độ tương tự của từng cặp items
# Calculate similarily
for i in range(0, len(data_item_base_frame.columns)):
# Loop through the columns for each column
for j in range(0, len(data_item_base_frame.columns)):
# Calculate similarity
data_item_base_frame.ix[i, j] = 1 - cosine(data.ix[:, i], data.ix[:, j])
Ở đây chúng ta sử dụng độ đo tương tự chính là 1- khoảng cách cosin đơn giản là vì khoảng cách cosin trả về giá trị từ 0 đến 1. Và đảm bảo được tính chất ***khoảng cách càng nhỏ thì độ tương tự càng lớn.***. Sau khi tính toán xong độ tương tự và cập nhật lại vào DataFrame lưu ở biến data_item_base_frame chúng ta sẽ có một ma trận độ tương tự của các item như sau:  Do dữ liệu này mất khá nhiều thời gian tính toán nên mình khuyên các bạn nên lưu nó vào một file CSV để lần sau dùng lại cho đỡ mất thời gian chạy lại vòng lặp phía trên:
Do dữ liệu này mất khá nhiều thời gian tính toán nên mình khuyên các bạn nên lưu nó vào một file CSV để lần sau dùng lại cho đỡ mất thời gian chạy lại vòng lặp phía trên:
data_item_base_frame.to_csv('data_item_base_frame.csv', sep=',', encoding='utf-8')
Việc cần làm tiếp theo đó là lọc ra các láng giềng có độ tương tự lớn nhất với từng items. Chúng ta sẽ sử dụng vòng lặp để sắp xếp chúng như sau:
for i in range(0, len(data_item_base_frame.columns)):
data_neighbors.ix[i,:10] = data_item_base_frame.ix[0:, i].order(ascending=False)[:10].index
print data_neighbors
Ở đây chúng ta cần lấy 10 items có độ tương tự gần nhất với item hiện tại và chúng ta sẽ sử dụng chúng để gợi ý cho người dùng khi người dùng click vào bài nhạc của chúng ta. Và kết quả như sau:
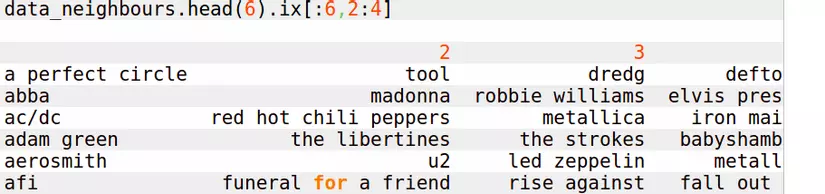
Khi mỗi người dùng vào một bài hát A, hệ thống sẽ tham chiếu trong bảng dữ liệu này và đưa ra gợi ý cho các bài hát tương tự như bài hát A. OK vậy là mình đã cùng với các bạn xây dựng xong một hệ gợi ý sử dụng phương pháp Lọc cộng tác dựa trên Item. Bài tiếp theo chúng ta sẽ tiếp tục với việc xây dựng một hệ gợi ý dựa trên phương pháp Lọc cộng tác dựa trên User Các bạn hãy đón chờ nhé.
Source Code
Các bạn có thể tham khảo source code của bài viết ở đây
To be continue
Ý kiến bạn đọc
- Đang truy cập59
- Hôm nay12,310
- Tháng hiện tại279,083
- Tổng lượt truy cập13,752,195